

Main Ideas
Lightweight Threads
 |
How to provide the effective computational load of multiple simple CPU cores? How to organize access of multiple computing threads to shared memory without conflicts and excessive overhead expenses?
If a task can be divided into independent subtasks, then the subtasks can be accomplished by a great number of execution cores with ability of fast switching between subtasks. Typically, various cores perform diverse blocks of software code. The calculation results are stored in shared memory or transmitted from a child thread to a parent thread. In the established terminology such concept is called ‘lightweight threads’. The important part is to provide the spawning mechanism of simultaneously executed threads on the processor level, not on the OS level. Theoretically, the overhead cost of such thread call is on a par with the ordinary function execution expenses. In C language thread spawning may look like this:
void start_thread(int(*)(int), int, ...);
Such a call can be performed by any core. The function needs to give a pointer to an executed function, number of arguments and, particularly the arguments if those exist.
The call along with the atomic non-blocking operations of increment and with some other standard operations create an ability to spawn and to join the simultaneously executed threads groups generating series-parallel processor program with many computing cores.
Smart Memory
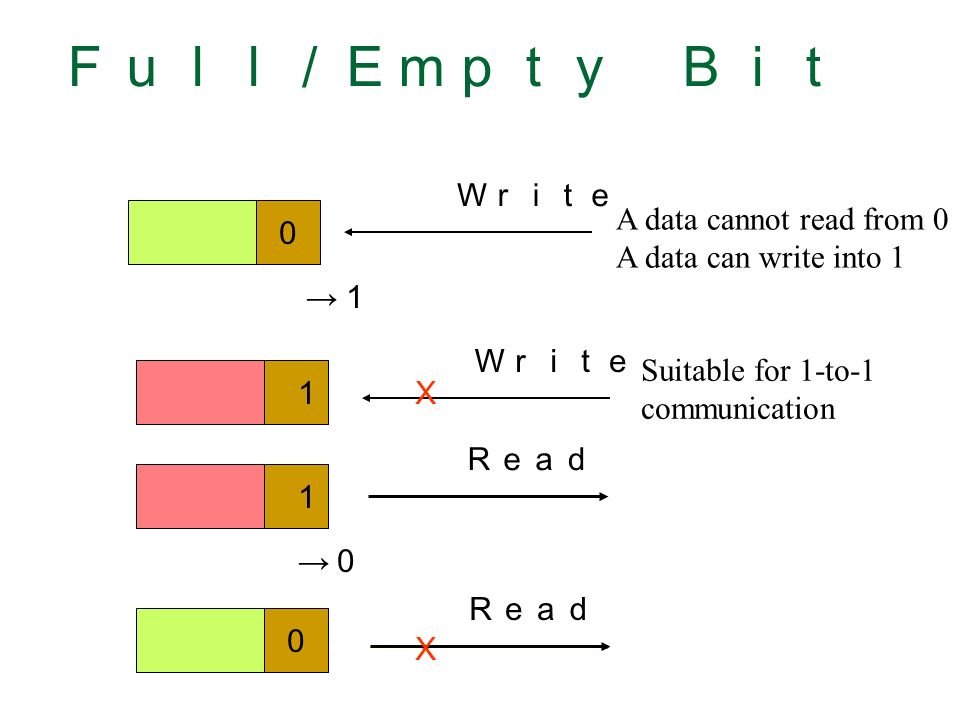
By the term ‘smart memory’ is meant a memory with additional features of data and ability to manipulate data based on these features on the memory controller level without the direct participation of computing processor cores. One of the most known types of memory is shared memory with FE bits where an extra bit is added to each of the memory words. The bit may be defined as ‘full’ if the slot consists date or ‘empty’ in other case. At attempt of reading the information from an empty slot, the reading core or the thread will be stopped untill the data appears in the slot.
Thus, the simultaneous operation of several threads with shared memory is provided without global locks. The FE-bit specification is enough to ensure synchronization of any number of simultaneous executable processes, also on the basis of this approach any atomic operations may be performed. The FE-bit mechanism key features:
– FE mechanism doesn’t generate global locks;
– FE mechanism may be used for locks of any granularity;
– FE mechanism doesn’t use polling;
– FE mechanism doesn’t consume resources of waiting threads.
The smart memory is not only FE bits. The smart controller helps to solve the interaction problem of multiple computing threads with shared resource in general and with shared memory in particular, including implementation of:
– ‘real’ atomic operations in memory;
– ‘instruction execution in memory’, for instance, i++ or indirect addressing;
– ‘DMA without DMA’, i.e. block operations performed without separate DMA controller;
and much more!
‘Dark’ Silicon
With increasing number of transistors and complexity of technological process the transistor leakage currents rise, as a result, the power consumption increases as well. These impacts are perceptible on technological processes below 90 nm, they must be taken into account using 28 nm and more modern chip technology. The estimated power consumption that could be achieved on a modern processor with 50% toggle rate (switching each transistor on the chip once per two clocks on average) exceeds a given thermal design power (TDP) constraint by 1-2 orders. It means, that a considerable part of the chip has to be inactive during the operation in order to provide the appropriate power consumption corresponding to the specified level. That part is named as ‘dark’ silicon.
The ‘dark’ silicon is not only inactive memory blocks and automatically turned off at particular clock by clock gating functional elements at a given moment, but, mainly, is large specialized processor units idle ‘at this moment’ and preserved by reduction of the clock speed, undervoltaging or switched to 'hibernate'. The concept of ‘dark’ silicon enables to place a larger amount of computing units on the processor chip, more than specified TDP would allow. And it preserves units that are currently not needed to be used or can’t be used due to the energy considerations.
Real Manycore and Multithreading
 |
|
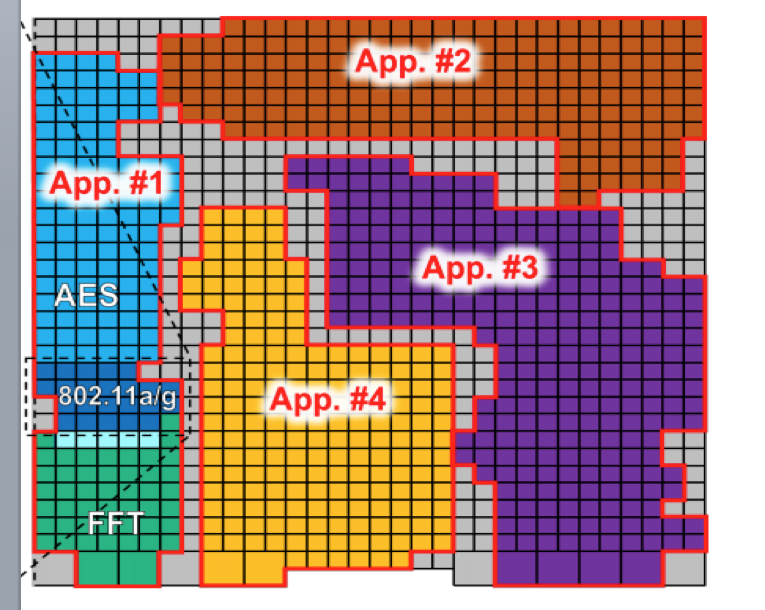
The example of application implementation on various core groups of Kilocore processor |
Classic temporal multithreading is based on implementation of various tasks on a single physical processor core when a thread is executed until there is a hardware interrupt, system call or until the alloted by the OS time is up. After that, the core switches to another thread under OS control that switches contexts. In multicore architectures the temporal multithreading has a feature of executing a thread on one of multiple physical cores. Simultaneous multithreading, for example, hyper-threading in the Intel processors, enables to run several threads on a single physical core. Such approaches are relevant when the required number of running tasks considerably exceeds the number of computing cores.
We come up technologically to processing manycore architectures capable to provide the user hundreds to thousands cores in every task. Where do we get so many threads? Certainly, by spawning, using the specification of lightweight threads at the user code level! How many threads will be running on a single core? According to the ‘dark’ silicon concept, no more than one! How will the processor resources be divided between several tasks? Trivially, each of the tasks gets as many cores as it needs and still there will be surplus cores left! That is what we call real manycore and multithreading.
Compact Processing Cores
 |
 |
|
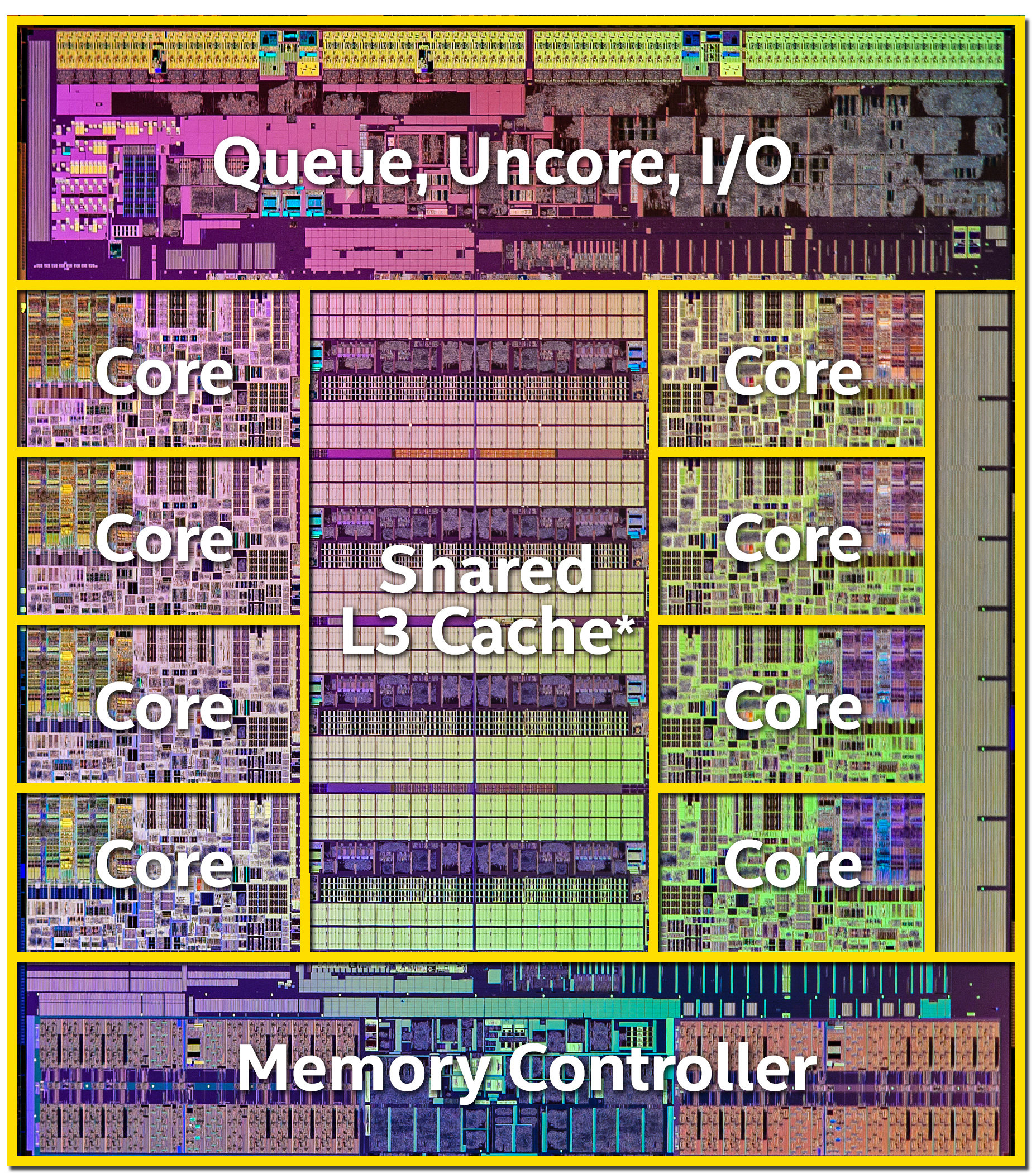
The Intel 8080 chip 4800 transistors. |
The Intel Core i7-5960X chip, 2,6 bln transistors. |
The first-generation of 8-bit processors was extremely compact. Thus, Intel 8080 has only 4800 transistorsand has been given value 0.1 MIPS/Mhz. The classic Pentium P54C core сcontains 3.2 bln transistors and has productivity of 1.7 MIPS/Mhz. The modern Intel Core i7 contains several billions of transistors and has productivity of 10 MIPS/Mhz. Surely, MIPS
is not the most objective indicator of computing core productivity and MIPS/Mhz is not the best performance index of an architecture, however, it’s hard to ignore the decrease of MIPS/Mhz-per-transistor index by three orders.
What is the reason of that? Briefly, the reason is that in reality, calculations are not the main task of the core. The calculation support, especially concerning the memory tasks, - that’s what requires millions of transistors. We reckon, it’s necessary to get back to compact processing cores, significant part of which (by the number of involved transistors) performs the target processing task or other one. How to act in a situation, when there are many tasks and each of them requires various core architectures? Should we create a universal architecture suitable for all tasks? In other words, should we create a billion-of-transistors ‘monster’? Absolutely not! We think, the right approach is to create as many various programmable cores as it needs, keeping each core extremely compact.
The Chip Device Specialization
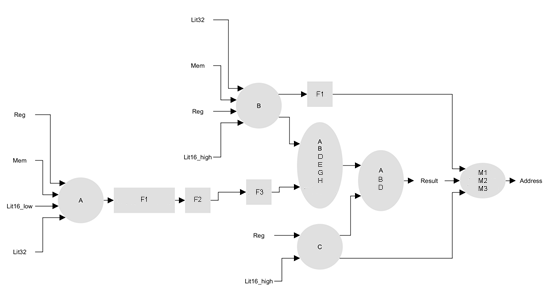
It would be wrong to analyze the productivity or energy efficiency in general. Those key processor parameters may be considered only in a context of particular task where they are measured. If an individual computer is created for each class of tasks and the developers of such devices have the equal qualification, financial and technological capabilities, the chip efficiency will be determined by specialization, i.e. by the narrowness of chosen class of tasks - the more narrow, the more effective it is. The majority of such specific computers would belong to the class of unprogrammed VLSI (VLSI on hard-coded logic operation).
ТThat’s how it works in practice: if a target class of tasks is in high demand, it will require millions of chips, for example, VLSI for cryptocurrency mining like Bitcoin. The chip energy efficiency surpasses the general-purpose processor on a specific task by 2-3 orders. Nevertheless, it often happens, that a class of tasks is not so specific to use a single unprogrammed chip and development of a whole range of specific processing units for various subclasses is not justified neither financially, nor technically. The classic solution is to select a universal architecture computer - CPU/GPU or FPGA.
Does any other way exist? Yes, it does. The specialization of the chip computing units. Such approach is commonly used for energy efficiency improvement in the development of network processors, graphics cards, portable device processors. You can think of them as of specific computing units for network packet processing, rendering computer game scenes or mobile content reproduction. If we’ve just mentioned your issue above, you have the solution already! If not then, perhaps, the energy efficient processor specifically tailored to your needs is going to be designed!
We assume, a processor may be truly energy efficient only if it’s created for a special class of tasks. We offer the specialization based on programmable computing units on the chip.
No cache coherency
Cache coherence is a maintenance mechanism of data integrity stored in a local cache of individual devices in the multiprocessor or multicore system, it is an individual case of memory coherence. This mechanism enabled to preserve the programmer’s illusion of a high-speed shared data memory on transition from single-core to manycore processors. The overhead expenses of cache coherence for multiple-core systems were acceptable.
The situation had changed with the transition to processors of dozens and hundreds cores, the cache coherence requiring ‘all-to-all’ low-latency communication became exceptionally difficult and energy consuming resource. Thus, the surface of a modern cache controller greatly exceeds the size of a standard 32-bit RISC core. There were some brilliant ideas, for example, created in 2013 100-core Tilera Tile-Gx with the intracrystal cache-coherence iMesh network, but it didn't get wide acceptance.
We think, cache coherence must be forgotten as one of the vestiges remaining from single-core era. It has to be replaced by software-controlled asynchronous shared memory with an architecture similar to NUMA. The applications determine themselves when and where the local and global memory block synchronization is required.
С/С++ Programming
Perhaps, it’s hard to find more rapidly developing field than programming. New languages emerge every year, meanwhile the old ones change beyond recognition. The development moves both in the direction of greater abstraction and in the direction of better hardware features reflection. On the other hand, programmers are extremely conservative, there is a huge amount of the system and applied libraries inherited from the past millennium. This leads us move on with having С/С++ languages as a must-have for any developed architecture. Hardware designers often ignored that and either offered the assembler language to the user, or invented a new high-level language. The result was always the same - oblivion.

We consider C or С/С++ support (presumably with certain restrictions) to be essential on any levels of programming of developed architectures - from a special processing element to general-purpose cores and computing system in general. We think, the user must be provided with basic С/С++ libraries or their decent subset that would effectively perform on the target architecture. We assume that at first the user needs to get a working С/С++ code for the target architecture, and then, using our Optimization guide, increase its productivity to the required level.
