

Основные идеи
Легкие потоки
 |
Как обеспечить возможность эффективной вычислительной загрузки множества простых процессорных ядер? Как упорядочить доступ множества вычислительных потоков к общей памяти без конфликтов и чрезмерных накладных расходов?
Если задача может быть разделена на независимые друг от друга подзадачи, то они могут быть выполнены множеством исполнительных ядер с возможностью быстрого переключения между подзадачами. В общем случае различные ядра могут выполнять различные блоки программного кода. Результаты вычислений сохраняются в общей памяти или передаются из “дочернего” в “материнский” поток. В относительно устоявшейся терминологии это называется "легкие потоки". Здесь важно обеспечить механизм порождения параллельно исполняемых потоков на уровне процессора, а не на уровне операционной системы. В идеале накладные расходы на вызов такого потока сравнимы с затратами при вызове обычной функции. В рамках языка C порождение потока можно описать вызовом вида:
void start_thread(int(*)(int), int, ...);
Такой вызов может быть произведен с любого ядра. Функции нужно передать указатель на запускаемую функцию, количество аргументов и собственно аргументы, если таковые имеются.
Такой вызов совместно с атомарными неблокируемыми операциями инкремента и некоторыми другими стандартными операциями создает возможность порождать (spawn) и объединять (join) группы параллельно выполняемых потоков, создавая последовательно-параллельную программу для процессора со множеством вычислительных ядер.
Умная память
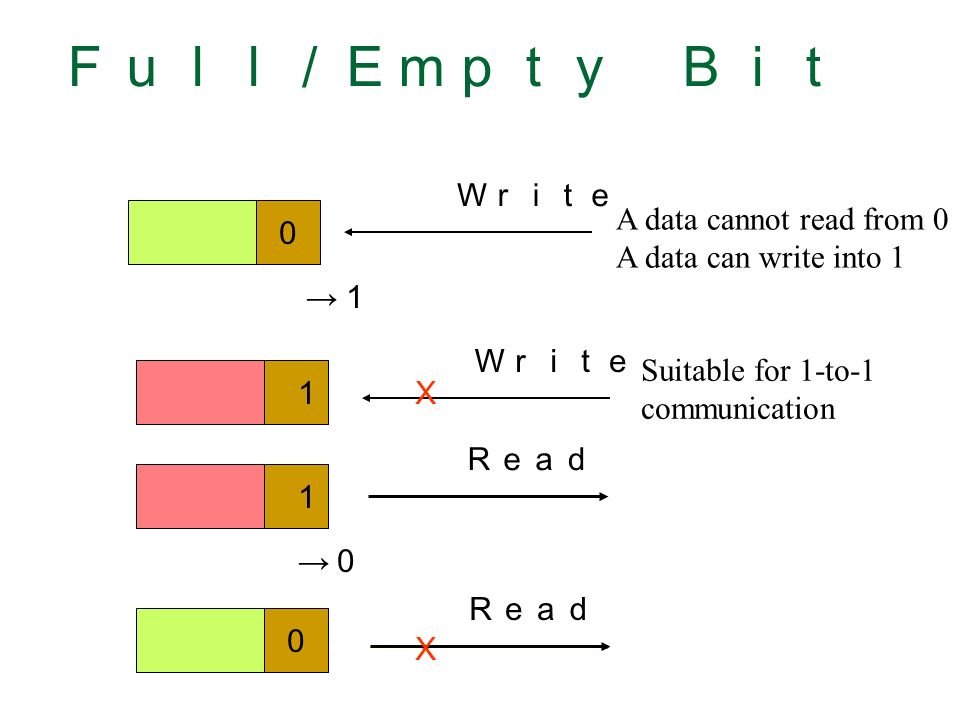
Под «умной памятью» обычно понимают память с дополнительными признаками данных и возможностью манипулировать данными на основе этих признаков на уровне контроллера памяти без непосредственного участия вычислительных процессорных ядер. Одним из наиболее известных типов такой памяти является общая память с FE-битами, в которой к каждому слову памяти добавляется один дополнительный бит. Этот бит может принимать значения “full”, если ячейка содержит информацию или “empty” в противном случае. При попытке считать информацию из пустой ячейки, считывающее ядро или поток будет приостановлено до тех пор, пока в ячейке не появятся данные.
Таким образом, на аппаратном уровне обеспечивается одновременная работа множества потоков с общей памятью без глобальных блокировок. Формализма FE-битов достаточно, чтобы обеспечить синхронизацию любого заданного количества параллельно исполняемых процессов, в том числе на базе этого подхода можно сделать любые атомарные операции. Ключевые особенности механизма FE битов:
– FE механизмы не порождают глобальных блокировок,
– FE механизмы могут использоваться для блокировок любой гранулярности,
– FE механизмы не используют механизмы опросов,
– FE механизмы не потребляют ресурсы ожидающих потоков.
Но умная память это не только FE-биты. Умный контроллер позволяет решить проблемы взаимодействия множества вычислительных потоков с общим ресурсом вообще и общей памятью в частности, в том числе реализовать:
– “настоящие” атомарные операции в памяти,
– “исполнение инструкций в памяти”, например i++ или косвенная адресация,
– “DMA без DMA” т.е. блочные операции, реализуемые без отдельного DMA контроллера,
и многое другое!
Темный кремний
По мере увеличения числа транзисторов и усложнения технологических процессов растут токи утечки в транзисторе и, как следствие, растет энергопотребление. Эти эффекты заметны на тех. процессах ниже 90 нм, их необходимо учитывать на 28 нм и более новых чипах. Расчетное энергопотребление, которое может быть достигнуто на современном процессоре при toggle rate 50% (переключении каждого транзистора на кристалле один раз за два такта в среднем), на 1-2 порядка превышает TDP (требования по теплоотводу). Это значит, что значительная часть кристалла во время работы должна бездействовать, чтобы обеспечить соответствующее заданному уровню энергопотребление. Эта часть получила название «темный» кремний.
«Темный» кремний - это не только не используемые в настоящий момент части блоков памяти и автоматически выключенные на определенных тактах с помощью механизма clock gating’а функциональные элементы, но, в первую очередь, крупные специализированные узлы процессора, не нужные “именно сейчас” и законсервированные путем снижения тактовой частоты, понижения напряжения питания или переведенные в режим “сна”. Концепция "темного кремния" позволяет размещать на кристалле процессора заведомо большее число вычислительных блоков, чем может быть задействовано единовременно в рамках заданного TDP, и консервировать те из них, которые на данный момент не нужны или не могут быть задействованы по энергетическим соображениям.
Настоящая многоядерность и многопоточность
 |
|
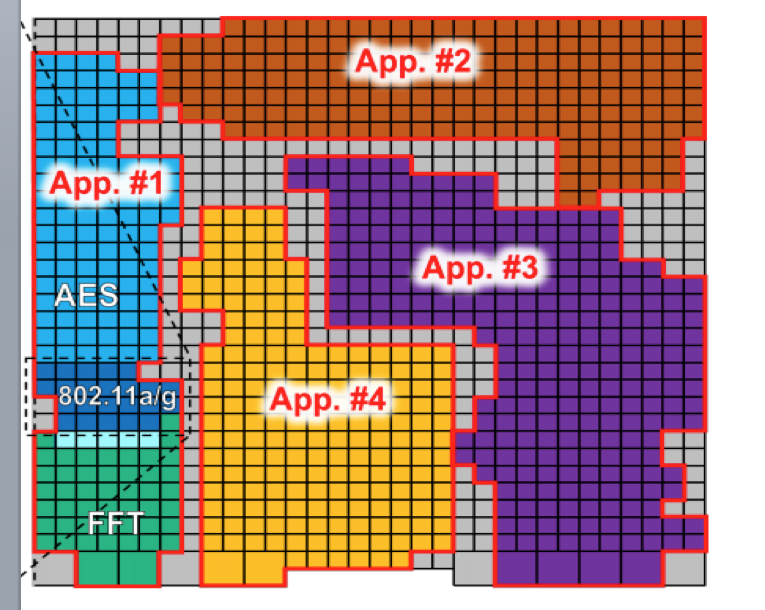
Пример исполнения приложений на различных группах ядер процессора Kilocore |
Классическая временная многопоточность (temporal multithreading) основана на исполнении нескольких задач на одном физическом ядре процессора, когда поток исполняется до тех пор, пока не произойдёт аппаратное прерывание, системный вызов или пока не истечёт отведённое для него операционной системой время, после этого ядро переключается на другой поток под управлением операционной системы, переключающей контексты. В multicore архитектурах temporal multithreading дополнен возможностью запустить поток на одном из нескольких физических ядер, одновременная многопоточность (simultaneous multithreading), например hyper-threading в процессорах компании Intel, позволяет запустить на одном физическом ядре несколько потоков. Эти подходы актуальны, когда требуемое количество исполняемых задач существенно превышает количество вычислительных ядер.
Однако сейчас мы технологически приходим к процессорным manycore архитектурам, способным предоставить на каждую задачу пользователя сотни или тысячи ядер. Где взять столько потоков? Конечно породить, используя формализм легких потоков на уровне пользовательского кода! Сколько же потоков будет исполняться на одном ядре? В соответствии с концепцией темного кремния - не более одного! Как будут распределяться ресурсы процессора между несколькими задачами? Тривиально, каждая задача получит столько ядер, сколько нужно, и еще останется! Именно это мы называем настоящей многоядерностью и многопоточностью.
Компактные вычислительные ядра
 |
 |
|
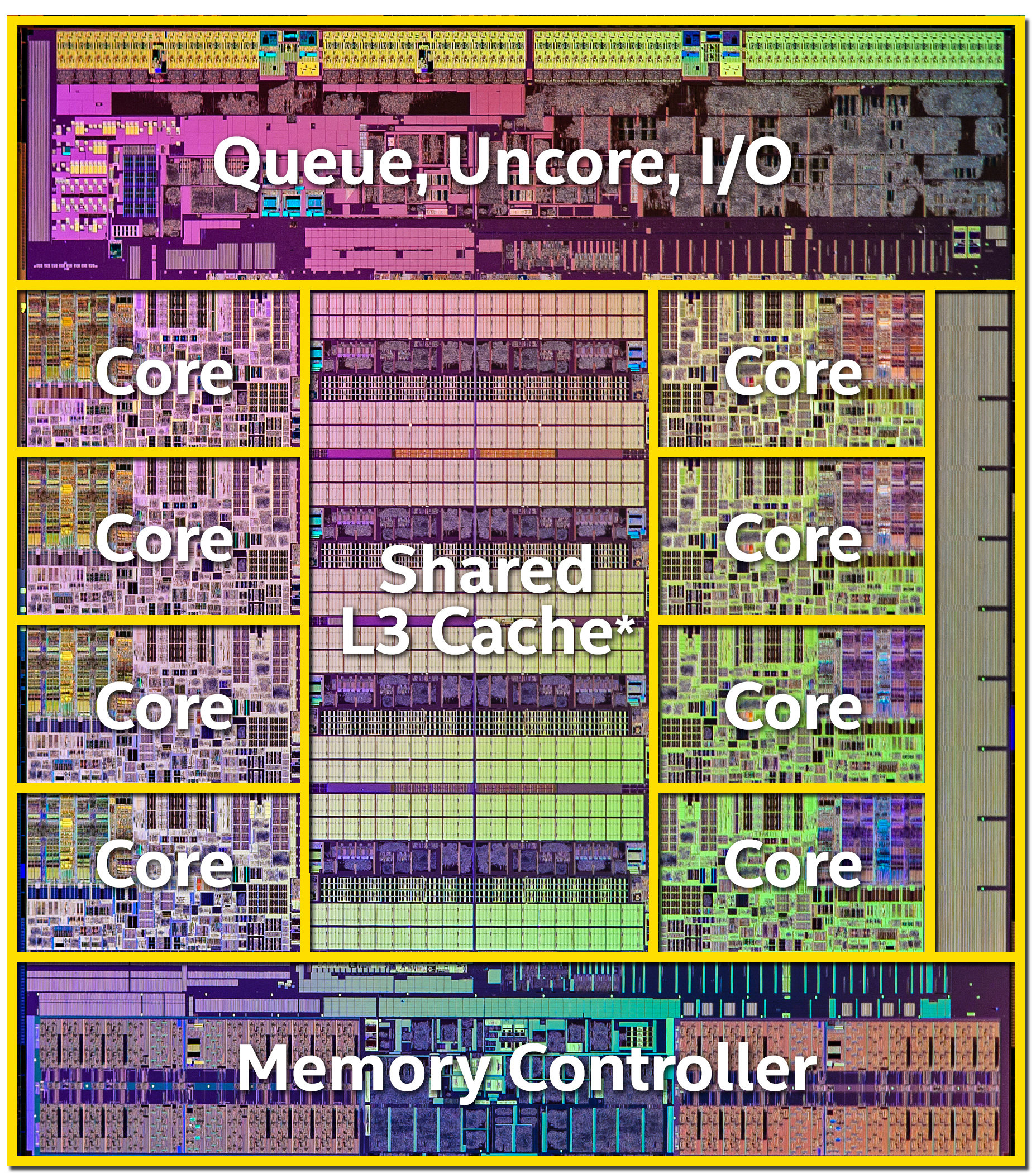
Кристалл intel 8080. 4800 транзисторов. |
Кристалл intel core i7-5960X. 2,6 млрд. транзисторов. |
Первые 8-битные процессоры были предельно компактными, так Intel 8080 содержал всего 4800 транзисторов и имел производительность на уровне 0.1 MIPS/Mhz. Классическое ядро Pentium P54C содержало 3,2 миллиона транзисторов и имело производительность на уровне 1.7 MIPS/Mhz. Современный Intel Core i7 содержит несколько млрд. транзисторов и имеет производительность порядка 10 MIPS/Mhz. Да, MIPS не самый объективный показатель производительности вычислительного ядра, а MIPS/Mhz - не самый лучший индекс эффективности архитектуры, но снижение показателя MIPS/Mhz/транзистор на три порядка сложно не заметить.
В чем причина? Если кратко, причина в том, что собственно вычисления перестали быть основной задачей ядра. Поддержка вычислений, в первую очередь в части работы с памятью, - вот что сегодня требует миллионов транзисторов. Мы считаем, что необходимо вернуться к компактным вычислительным ядрам, заметная часть которых по числу задействованных транзисторов выполняет целевую вычислительную или иную задачу. Как быть в ситуациях, когда задач много и для них оптимальны различные архитектуры ядра? Сделать универсальную архитектуру, пригодную для всех задач, т.е. создать еще одного монстра с миллиардом транзисторов? Нет! Мы считаем, что нужно делать столько различных программируемых ядер, сколько нужно, оставляя каждое ядро предельно компактным.
Специализация устройств на кристалле
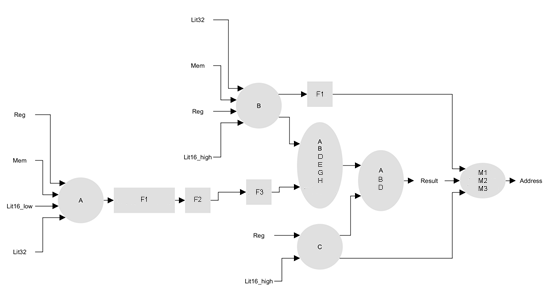
Нельзя говорить о производительности или энергоэффективности вообще, эти ключевые показатели процессора могут рассматриваться только в контексте конкретной задачи, на которой измерены. Если бы под каждый класс задач создавался отдельный вычислитель, а разработчики таких устройств имели равную квалификацию, финансовые и технологические возможности, то эффективность чипа определялась бы только специализацией, т.е. узостью выбранного класса задач: чем уже, тем эффективнее. Большинство таких спецвычислителей относились бы к классу непрограммируемых СБИС, т.е. СБИС с жестко заданной логикой работы.
Так на практике и происходит, если целевой класс задач настолько востребован, что требует миллионы чипов, как, например, СБИС для майнинга криптовалют типа биткоин. Их энергоэффективность на конкретной переборной задаче превосходит на 2-3 порядка процессоры общего назначения. Однако очень часто класс задач не столь узок, чтобы обойтись одним непрограммируемым чипом, а разработка целого ряда спецвычислителей под все возможные подклассы не оправдана ни экономически, ни технически. Классический выход из этого тупика - выбор вычислителя с универсальной архитектурой, CPU/GPU или ПЛИС.
Есть ли другой путь? Да, есть. Это специализация на уровне вычислительных блоков на кристалле. Такой подход для повышения энергоэффективности уже широко используется при разработке сетевых процессоров, графических карт, процессоров для мобильных устройств, каждый из которых можно рассматривать как спецвычислитель для задачи обработки сетевых пакетов, рендеринга сцен в компьютерных играх или воспроизведения мобильного контента. Если среди перечисленного выше есть ваша задача, то решение для вас уже создано! Если же нет, то, возможно, энергоэффективный процессор под вашу задачу еще только предстоит создать!
Мы считаем, что процессор может быть по-настоящему энергоэффективным, только если он создан под определенный класс задач. Мы предлагаем специализацию на уровне программируемых вычислительных блоков на кристалле.
No cache coherency
Когерентность кэша (cache coherence) — механизм поддержания целостности данных, хранящихся в локальных кэшах отдельных устройств в многопроцессорной или многоядерной системе, частный случай когерентности памяти. Этот механизм позволил при переходе от одноядерных к многоядерным процессорам сохранить у программиста иллюзию быстрой общей памяти данных. Накладные расходы на когерентность кэша для систем из нескольких ядер были допустимыми.
Ситуация изменилась при переходе к процессорам с десятками и сотнями ядер, когерентность кэша данных, требующая низколатентной связи “всех со всеми”, стала исключительно сложным и энергопотребляющим ресурсом. Так площадь современного кэш-контроллера многократно превышает размер базового 32-битного RISC ядра. Были на этом пути и гениальные решения, например созданный в 2013-том 100-ядерный Tilera Tile-Gx с внукрикристальной кэш когерентной сетью iMesh, который однако не получил широкого распространения.
Мы считаем, что когерентность кэшей должна отмереть, как один из рудиментов, оставшихся от одноядерной эры, ей на замену должна прийти программно-управляемая асинхронная распределенная память с NUMA-подобной архитектурой, в которой приложения сами определяют, когда и где необходима синхронизация блоков локальной и глобальной памяти.
Программирование на С/С++
Наверно, сложно найти более динамично развивающуюся сегодня область, чем программирование. Новые языки возникают каждый год, а старые меняются до неузнаваемости. Совершенствование идет как в сторону большей абстрактности, так и в сторону лучшего отражения особенностей аппаратуры. С другой стороны, программисты исключительно консервативны, огромный объем кода системных и прикладных библиотек унаследован из прошлого тысячелетия. Эти соображения переносят языки С/С++ в раздел must-have для любой разрабатываемой архитектуры. Разработчики железа неоднократно игнорировали это соображение, либо предлагая пользователю ассемблер, либо создавая собственный высокоуровневый язык, результат всегда был одинаковым - забвение.

Мы считаем поддержку С или С/С++, возможно с некоторыми ограничениями, необходимой на всех уровнях программирования разрабатываемых архитектур от специализированных процессорных элементов до ядер общего назначения и вычислительной системы в целом. Мы считаем, что пользователю должны быть предоставлены базовые С/С++ библиотеки или их разумное подмножество, эффективно исполняемое на целевой архитектуре. Мы считаем, что сначала пользователь должен быстро получить рабочий код на С/С++ для целевой архитектуры, а потом, пользуясь нашим Optimization guide, поднять его производительность до необходимого уровня.
