

The development of MALT-processors with vector and mixed architecture has been started
- Details
- Published: Sunday, 16 August 2015 17:27
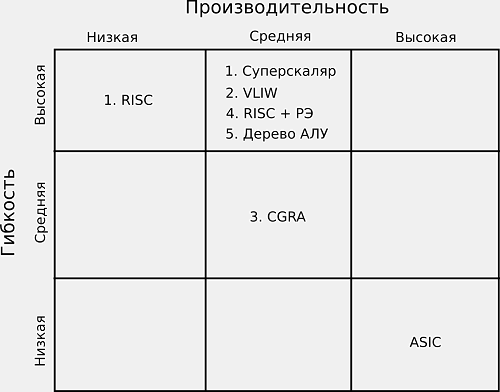 |
A comparison of processing elements’ options by the ratio “performance-flexibility” Photo: maltsystem.com |
The development of MALT-processors with vector and mixed architecture has been started.
Solutions of mathematical tasks with the ultimate level of complexity from the field of discrete mathematics with perfect or almost perfect parallelization of data with regards to compact (according to core size) and particularly complex mathematical procedures may be energy-efficient implemented only on specialized programmed or configurable computing structures on FPGA/VLSI or in the form of CPU/GPU blocks.
The first approach (implementation on FPGA/VLSI) is trivial - the maximum possible number of identical specialized computers are placed on a chip, an interface of every computer towards a control machine is a set of registers for receiving input data, giving out data output, control, indication of the specialized computer current state. On the one hand, the approach characterized by maximum density of computers, but, on the other hand, it may generate intensive data exchange between the host system and VLSI in order to control calculations and timely load all the computers.
The second approach (specialized block implementation on general-purpose CPU/GPU) turns out to be more flexible, it enables to “approximate a universal core to a specialized computer”. On the other hand, the approach is less productive concerning the maximum theoretically achievable performance value in test tasks, it requires complex tools development. Thus, it seems reasonable to offer VLSI/FPGA a structure combining conventional processor easy programming and maintaining a high level of performance determined by specialized computers.
As a result of computing systems’ analysis, the possible solution for target tasks is to offer a large array of SIMD accelerators controlled by simple RISC processors, which execute code written in C-language. The analysis of processing element architectures to evaluate effectiveness of their usage within the SIMD accelerator array determined that the most promising option is a processor element based on ALU tree architecture. This approach has a high flexibility, average performance index and optimal characteristics of energy efficiency. For basic algorithm calculation there has been chosen a set of commands allowing to implement a batch of basic RISC operations per one cycle due to the highest performance in comparison with other analyzed approaches.
