

Начато проектирование MALT-процессоров с векторной и смешанной архитектурами
- Информация о материале
- Опубликовано: 16.08.2015, 20:27
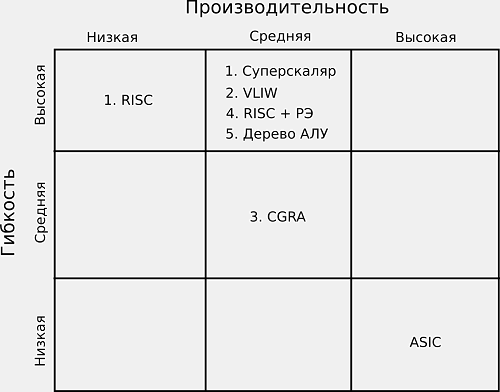 |
Сравнение вариантов процессорных элементов на предмет соотношения "производительность-гибкость" Изображение: maltsystem.com
|
Начато проектирование MALT-процессоров с векторной и смешанной архитектурами.
Решение математических задач предельной сложности из области дискретной математики с идеальным или близким к идеальному распараллеливанием по данным в части компактных по размеру кода и особо сложных математических процедур может быть выполнено энергоэффективно только на специализированных программируемых или конфигурируемых вычислительных структурах, реализованных на ПЛИС/СБИС или в виде специализированных блоков в CPU/GPU.
Первый подход (реализация на ПЛИС/СБИС) тривиален, на кристалле размещают максимально возможное количество идентичных специальных вычислителей, интерфейс каждого вычислителя к управляющей машине представляет из себя набор регистров для приема входных данных, выдачи выходных данных, управления, индикации текущего состояния спецвычислителя. Такой подход, с одной стороны, характеризуется максимальной плотностью вычислителей, но с другой - может порождать интенсивный обмен данными между хост-системой и СБИС для управления вычислениями и своевременной загрузкой всех вычислителей.
Второй подход (реализация специализированных блоков в CPU/GPU общего назначения) оказывается более гибким, позволяет "приблизить универсальное ядро к спецвычислителю". С другой стороны, такой поход менее производителен в части максимального теоретически достижимого значения производительности на тестовых задачах, требует разработки сложных инструментальных средств. Поэтому кажется логичным предложить в СБИС/ПЛИС структуру, с одной стороны, сочетающую простоту программирования обычного процессора, с другой - сохраняющую высокий уровень производительности, определяемый специальными вычислителями.
В результате проведенного анализа вычислительных системам для целевых задач можно предложить большой массив SIMD-ускорителей, управляющихся простыми RISC-процессорами, исполняющими код, написанный на Си. Анализ архитектур процессорных элементов на предмет эффективности их использования в рамках SIMD-массива ускорителя показал, что наиболее перспективен вариант процессорного элемента на основе архитектуры с деревом АЛУ. Такой подход обладает высокой гибкостью, средними показателями производительности и оптимальными характеристиками энергоэффективности. Для вычисления базовых алгоритмов был выбран набор команд, позволяющий выполнять связки базовых RISC-операций за один такт, в связи с наибольшей производительностью относительно всех других проанализированных подходов.
