- Информация о материале
-
Опубликовано: 31.10.2016, 19:36
 |
ПЛИС Stratix 10
Фото: intel
|
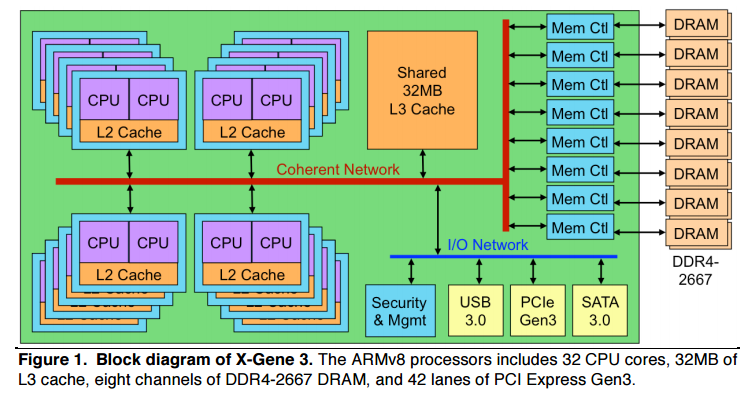
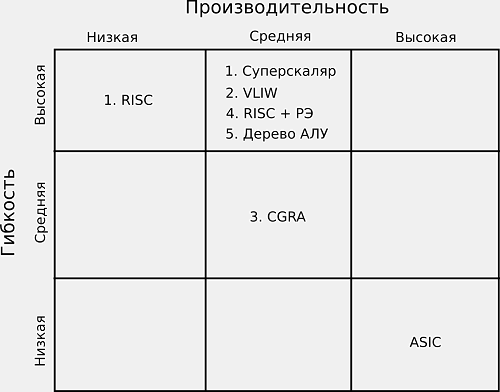
Корпорация Intel заявила, что апробирует Stratix 10 FPGA — новейшее семейство программируемых логических интегральных схем, специально разработанное для повышения производительности дата-центров. Новые устройства, которые Intel называет «наиболее серьезной ПЛИС-инновацией за последние десять лет», содержат современные продвинутые компоненты: 64-битные ARM-процессоры, память второго поколения — High Bandwidth Memory (HBM2) и DSP-блоки.
Рынок приложений, на который нацелено семейство Stratix 10, в некотором смысле уже занят акселераторами GPU от Nvidia и AMD, а также собственной платформой Intel - Knights Landing Xeon Phi. Однако в Intel считают, что такие нагрузки, как обработка сигналов, компрессия данных, шифрование, архивное хранение и обработка видео, переживают трудные времена во всех серверных приложениях, у которых главным критерием является производительность. Дополненные DSP-блоком, который даёт много дополнительных аппаратных FLOP, эти устройства также могут быть использованы для высокопроизводительных вычислений.
Подробнее...