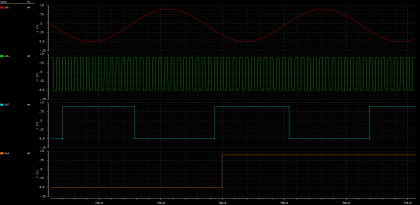
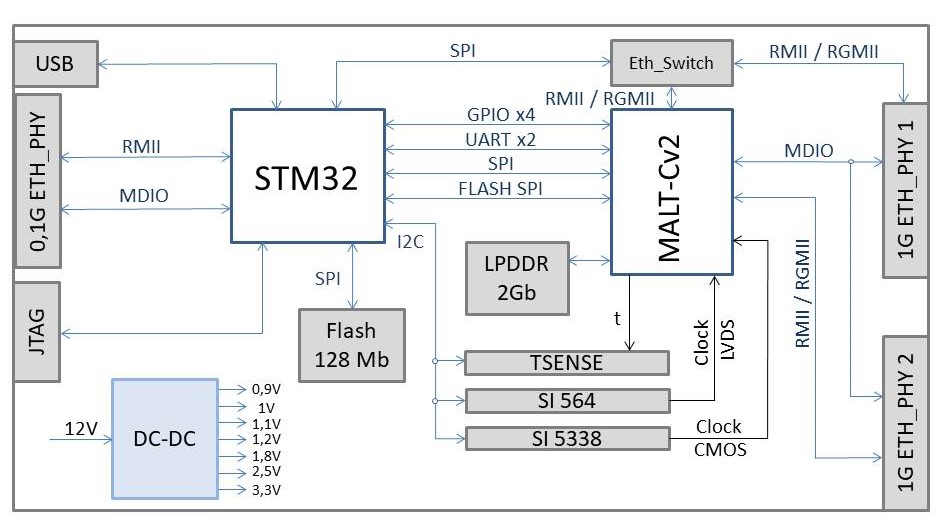
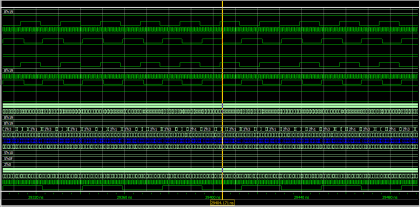
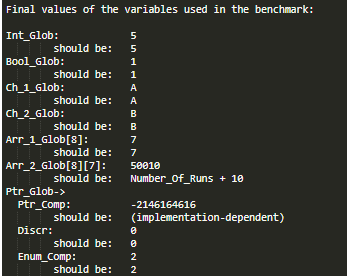
Мы переехали в новый офис
- Информация о материале
- Опубликовано: 02.11.2020, 10:00
 |
Мы растем и стремимся обеспечивать нашим сотрудникам комфортные условия для работы, особенно в условиях пандемии, которая ставит дополнительные требования к чистоте воздуха и площади рабочих помещений. Весной 2020 года, когда вопрос переезда назрел, мы собрали нашу команду и попробовали сформулировать, как мы видим подходящий нам офис. Вот что мы тогда написали...